Functional Breadth First Search
Functional depth first search is lovely in directed acyclic graphs.
In graphs with cycles however, how do we avoid infinite recursion? In a procedural language I would mark nodes as I hit them, but let's say I can't do that.
A list of visited nodes is possible, but will be slow because using one will result in a linear search of that list before recurring. A better data structure than a list here would obviously help, but that's not the aim of the game, because I'm coding in ML - lists are king, and anything else I will have to write myself.
Is there a clever way around this issue? Or will I have to make do with a visited list or, god forbid, mutable state?
One option is to use inductive graphs, which are a functional way of representing and working with arbitrary graph structures. They are provided by Haskell's fgl library and described in "Inductive Graphs and Funtional Graph Algorithms" by Martin Erwig.
For a gentler introduction (with illustrations!), see my blog post Generating Mazes with Inductive Graphs.
The trick with inductive graphs is that they let you pattern match on graphs. The common functional idiom for working with lists is to decompose them into a head element and the rest of the list, then recurse on that:
map f [] = []
map f (x:xs) = f x : map f xs
Inductive graphs let you do the same thing, but for graphs. You can decompose an inductive graph into a node, its edges and the rest of the graph.

(source: jelv.is)
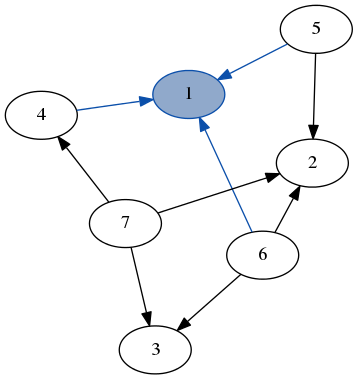{kind=link}
Here we match on the node 1 and all of its edges (highlighted in blue), separate from the rest of the graph.
This lets us write a map for graphs (in Haskellish pseudocode that can be realized with pattern synonyms):
gmap f Empty = Empty
gmap f ((in, node, out) :& rest) = f (in, node, out) :& gmap f rest
The main shortcoming of this approach as opposed to lists is that graphs do not have a single natural way to decompose: the same graph can be built up in multiple ways. The map code above would visit all the vertices, but in an arbitrary (implementation-dependent) order.
To overcome this, we add another construct: a match function that takes a specific node. If that node is in our graph, we get a successful match just like above; if it isn't, the whole match fails.
This construct is enough to write a DFS or a BFS—with elegant code that looks almost identical for both!
Instead of manually marking nodes as visited, we just recurse on the rest of the graph except the node we're seeing now: at each step, we're working with a smaller and smaller portion of the original graph. If we try to access a node we've already seen with match, it won't be in the remaining graph and that branch will fail. This lets our graph-processing code look just like our normal recursive functions over lists.
Here's a DFS for this sort of graph. It keeps the stack of nodes to visit as a list (the frontier), and takes the initial frontier to start. The output is a list of nodes traversed in order. (The exact code here can't be written with the library directly without some custom pattern synonyms.)
dfs _frontier Empty = []
dfs [] _graph = []
dfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
dfs (neighbors' ctx ++ ns) rest
dfs (n:ns) graph = -- visited n
dfs ns graph
A pretty simple recursive function. To turn it into a breadth-first search, all we have to do is replace our stack frontier with a queue: instead of putting the neighbors on the front of the list, we put them on the back:
bfs _frontier Empty = []
bfs [] _graph = []
bfs (n:ns) (match n -> Just (ctx, rest)) = -- not visited n
bfs (ns ++ neighbors' ctx) rest
bfs (n:ns) graph = -- visited n
bfs ns graph
Yep, that's all we need! We don't have to do anything special to keep track of the nodes we visited as we recurse over the graph, just like we don't have to keep track of the list cells we've visited: each time we recurse, we're only getting the part of the graph we haven't seen.
- Python, Web Scraping
- Cannot scrape xpath using Selenium
- Scrapy script not scraping items
- why does the html all have same class and sub-class with different information
- Yfinace - Getting Too Many Requests. Rate limited. Try after a while
- Requests and BeautifulSoup to get video length from YouTube
- web scraping Proplem no such element
- Python/Selenium - Scraping Into Excel Sheet
- Scraping data using Network, Fetch, Response
- Python NLTK: Bigrams trigrams fourgrams
- Discovering Poetic Form with NLTK and CMU Dict
- Python Wand: MagickReadImage returns false, but did not raise ImageMagick exception
- Executing multi-line statements in the one-line command-line
- How to get the replit link for uptime robot?
- How to install TA-Lib On vscode/windows(64bit)
- Python injector doesn't work for NewType based on tuple[str, str]
- Python conditional list joins
- Why Can't VS Code Directly Run Python unittest .py's Or Discover In Testing Tab
- Limiting amount of objects user can add in another object
- I got warning as: "Name 'x' can be undefined" and "Global variable 'x' is undefined at the module level"
- How to split data into 3 sets (train, validation and test)?
- How can I set session details in conftest.py for yield along with fixture in pytest?
- Show DataFrame as table in iPython Notebook
- How to get all possible (2^N) combinations of a list’s elements, of any length
- Python Declare variables iteratively
- Quarto Unable to Render Python
- Filter pandas dataframe with specific column names in python
- Tkinter canvas image probably being garbage collected but creating a persistent reference does not solve the problem
- Why is Pipenv not picking up my Pyenv versions?
- Why do I get lots of terminal messages about files 'first seen with mtime' when starting django runserver?