Is Content Provider an implementation of Repository Pattern?
Repository Pattern is defined by Hieatt and Rob Mee as design pattern that mediates between the domain and data mapping layers using a collection-like interface for accessing domain objects.

Basically it abstracts one or more I/O devices (cloud, disk, data base, etc) into a common collection-like interface where you can read, write, seek and delete data.
On Fernando Cejas's Android Clean Architecture, all data needed for the application comes from this layer through a repository implementation (the interface is in the domain layer) that uses a Repository Pattern with a strategy that, through a factory, picks different data sources depending on certain conditions.
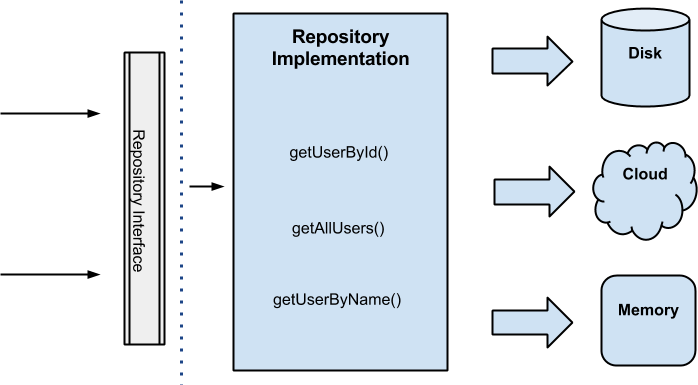
However, as pointed out by professor Douglas Schmidt at Coursera course, content provider manages and mediates access to a central repository of data to one or more applications

In the book Programming Android, content providers are used as a Facade for a RESTful Web Service. This approach was initially presented by Virgil Dobjanschi during Google I/O 2010.
Thus, instead of using content providers to access the local SQLite database, why not using it as the repository pattern itself?

Let's try to compare the Repository Pattern definition from the book "Patterns of Enterprise Application Architecture" by Martin Fowler
(with Dave Rice, Matthew Foemmel, Edward Hieatt, Robert Mee, and Randy Stafford) with what we know about ContentProviders.
The book states:
A Repository Mediates between the domain and data mapping layers using a collection-like interface for accessing domain objects.
The important bit is accessing domain objects. So at first glance it seems that the repository pattern is only meant for accessing (querying) data. With a ContentProvider, however, you not only can access (read) data but also insert, update or remove data.
However, the book says:
Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes.
So, yes Repository and ContentProvider seem to offer the same operations (very high level point of view) although the book explicitly states simple collection of objects which is not true for ContentProvider as it requires android specific ContentValues and Cursor from Client (who uses a certain ContentProvider) to interact with.
Also, the book mentions domain objects and data mapping layers:
A Repository Mediates between the domain and data mapping layers
and
Under the covers, Repository combines Metadata Mapping (329) with a Query Object (316) Metadata Mapping holds details of object-relational mapping in metadata.
Metadata Mapping basically means i.e. how to map a SQL column to a java class field.
As already mentioned ContentProvider returns a Cursor object from a query() operation. From my point of view a Cursor is not a domain object. Moreover, mapping from cursor to domain object must be done by the client (who uses a ContentProvider). So data mapping is completely missing in ContentProvider from my point of view. Furthermore, the client may have to use a ContentResolver too to get the domain object (data). In my opinion this API is a clear contradiction with the definition from the book:
Repository also supports the objective of achieving a clean separation and one-way dependency between the domain and data mapping layers
Next let's focus on the core idea of the Repository pattern:
In a large system with many domain object types and many possible queries, Repository reduces the amount of code needed to deal with all the querying that goes on. Repository promotes the Specification pattern (in the form of the criteria object in the examples here), which encapsulates the query to be performed in a pure object-oriented way. Therefore, all the code for setting up a query object in specific cases can be removed. Clients need never think in SQL and can write code purely in terms of objects.
ContentProvider requires a URI (string). So it's not really a "object-oriented way". Also a ContentProvider may need a projection and a where-clause.
So one could argue that a URI string is some kind of encapsulation as the client can use this string instead of writing specific SQL code for instance:
With a Repository, client code constructs the criteria and then passes them to the Repository, asking it to select those of its objects that match. From the client code's perspective, there's no notion of query "execution"; rather there's the selection of appropriate objects through the "satisfaction" of the query's specification.
ContentProvider using a URI (string) doesn't seem to contradict with that definition, but still misses the emphasized object-oriented way. Also strings are not reusable criteria objects that can be reused in a general way to compose criteria specification to "reduces the amount of code needed to deal with all the querying that goes on."
For example, to find person objects by name we first create a criteria object, setting each individual criterion like so: criteria.equals(Person.LAST_NAME, "Fowler"), and criteria.like(Person.FIRST_NAME, "M"). Then we invoke repository.matching(criteria) to return a list of domain objects representing people with the last name Fowler and a first name starting with M.
As you have already said (in your question) Repository is also useful to hide different data sources as an implementation detail the client doesn't know about. This is true for ContentProviders and specified in the book:
The object source for the Repository may not be a relational database at all, which is fine as Repository lends itself quite readily to the replacement of the data-mapping component via specialized strategy objects. For this reason it can be especially useful in systems with multiple database schemas or sources for domain objects, as well as during testing when use of exclusively in-memory objects is desirable for speed.
and
Because Repository's interface shields the domain layer from awareness of the data source, we can refactor the implementation of the querying code inside the Repository without changing any calls from clients. Indeed, the domain code needn't care about the source or destination of domain objects.
So to conclude: Some definitions from Martin Fowler et al. book match the API of a ContentProvider (if you ignore the fact that the book emphasized object-oriented):
- Hides the fact that a repository / ContentProvider has different data sources
- Client never has to write a query in a datasource specific DSL like SQL. That is true for ContentProvider if we consider URI as not datasource specific.
- Both, Repository and ContentProvider, have the same "high level" set of operations: read, insert, update and remove data (if you ignore the fact that Fowler talks a lot about object orientated and collection of objects whereas ContentProvider uses Cursor and ContentValues)
However, ContentProvider really misses some key points of the repository pattern as described in the book:
- Since ContentProvider uses URI (also string for the where clause) a client can't reuse Matching Criteria objects. That is an important thing to note. The book clearly says that the repository pattern is useful "In a large system with many domain object types and many possible queries, Repository reduces the amount of code needed to deal with all the querying that goes on". Unfortunately, ContentProvider doesn't have Criteria objects like
criteria.equals(Person.LAST_NAME, "Fowler")that can be reused and used to compose matching criterias (since you have to use strings). - ContentProvider miss entirely data mapping as it returns a
Cursor. This is very bad because a client (who uses a ContentProvider to access data) has to do the mapping of Cursor to domain object. Furthermore, that means that client has knowledge of repository internals like name of columns. "Repository can be a good mechanism for improving readability and clarity in code that uses querying extensively." That certainly is not true for ContentProviders.
So no, a ContentProvider is not a implementation of the Repository pattern as defined in the Book "Patterns of Enterprise Application Architecture" because it misses at least two essential things I have pointed out above.
Also, please note that as the name of the book already suggests, the repository pattern is meant to be used for Enterprise Application where you do a lot of queries.
Android developers tend to use the term "Repository pattern" but don't actually mean the "original" pattern described by Fowler et al. (high reusability of Criterias for queries) but rather mean a interface to hide the underlying data source (SQL, Cloud, whatever) and domain object mapping.
More here: http://hannesdorfmann.com/android/evolution-of-the-repository-pattern
- Exceptions for android 6/5 users after updating to latest version Google Play Billing Library (7.1.1)
- Flutter - save file to download folder - downloads_path_provider
- Could not load module metadata from
- Broadcast intent android.intent.action.BOOT_COMPLETED received every single time I run / update the app. Why?
- How to unscape text from database in android studio
- How to replace the deprecated kotlinOptions in a java-library & kotlin module?
- Android BLE Gatt connection change statuses
- Can Bubble.io be used to create mobile apps, including backend, frontend, and releasing native apps?
- Issues with Geckoview (Firefox webview) Graddle conflict (lollipop version)
- Is there an alternative to webview setInitialScale in GeckoView in Android
- Not able to use Coil library in Android View project with mixed Java-Kotlin code
- Mozilla Firefox Add-on Android - Page Action not working
- Load image from url
- How to scroll the RecyclerView programatically by a specific pixels?
- Can I use adb to change the default launcher program?
- How to convert Drawables to ImageVector to use as custom icons for NavigationBar?
- How to setup Android WebView to make it work identically Android browser?
- How to use LazyVerticalStaggeredGrid in scrollable column in jetpack compose?
- How to fix LinearProgressBar
- You uploaded a debuggable APK. For security reasons you need to disable debugging before it can be published in Google Play-Upload apk to google play
- compose.material3 TopAppBar has a color transition effect when switching between light and dark mode
- Confused about compileSdk vs minSdK: How is it possible, that it runs on very old devices?
- BackHandler on Compose Multiplatform (Android and iOS)
- How to use startNativeTracing
- Local notificaitons for flutter only works on emulator but not a real Android device?
- get launchable activity name of package from adb
- Android: MVVM and separation of concerns
- Update single item GoolgeMap Cluster
- How to record Android device's screen on Android version below 4.4 (KitKat)
- rememberSystemUiController Deprecated