Is the relationship between index tuple in GiST index and user table row many to one or one to one?
In a regular b-tree index, the leaf node contains a key and a pointer to the heap tuple (user table row), which signifies that in b-tree, the relationship between index tuple and user table row is one-to-one.
Just like in a b-tree, a GiST leaf node also contains a key datum and info about where the heap tuple is stored, but GiST leaves may or may not contain entire row data in its keys (please correct me if I'm wrong). So, if I am able to store one part of my table data in one leaf node and the other part in another leaf node and make both of them point to one heap tuple, would it be possible? This will make the relationship between GiST index tuple and heap tuple many to one.
Is all this correct?
A GiST index is a generalization of a B-tree index.
In a non-leaf block of a B-tree index, two consecutive index entries define the boundary for the indexed values in the subtree at the destination of the pointer between these index entries:
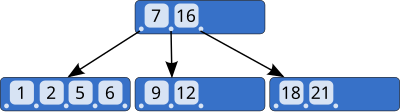
In other words, each pointer to the next lower level is labeled with an interval that contains all values in the subtree.
This only works for data types with a total ordering.
The GiST index extends that concept. Each entry in a non-leaf node has a condition that the subtree under that index entry has to satisfy.
When scanning a GiST index, I search the index page for all entries that may contain values matching my search condition. Since there is no total ordering, it is possible (but of course not desirable) that the conditions somehow “overlap” so that something I search for can have matches in more than one of the entries. In that case I have to descend into all the referenced subtrees, but I can skip those where the entry's condition guarantees that the subtree cannot contain entries that match my search condition.
This is a little abstract, so let's flesh it out with an example.
One of the classical examples of a GiST index is an R-tree index, a kind of geographical index like it is used by PostGIS:

Here the condition of an index entry is a bounding box that contains the bounding boxes of all geometries contained in the subtree of the index entry. So whan searching for a geometry, I take its bounding box and see which of the index entries in a page contains this bounding box. These are the subtrees into which I have to descend.
One thing that can be seen in this example is that a GiST index can be lossy, that is, it gives me a neccesary, but not sufficient condition if I have found a hit. The leaf entries found in a GiST index scan always have to be rechecked if the actual table entry also satisfies the condition (not every geometry is a rectangle). This is why a GiST index scan is always a bitmap index scan in PostgreSQL.
This all sounds nice and simple. The hard part about a good GiST index is the picksplit algorithm that decides upon an index page split which of the index entries comes into which of the two new index pages. The better this works, the more efficient the index will be.
So you see, a GiST index is “somewhat like” a B-tree index in many respects. You can see a B-tree index as an optimized special case of a GiST index (see the btree-gist contrib module).
This lets me answer your questions:
GiST leaf node also contains key datum and info about where the heap tuple is stored
This is true.
GiST leaves may or may not contain entire row data in its keys
Of course the index entry does not contain the entire row. But I think you mean the right thing. The condition in the GiST leaf can be broader than the actual object in the table, like a bounding box is bigger than a geometry.
if I am able to store one part of my table data in one leaf node and the other part in another leaf node and make both of them point to one heap tuple, would it be possible? This will make the relationship between GiST index tuple and heap tuple many to one.
This is wrong. Even though a value may satisfy several of the entries in a GiST index page, it is only contained in one of the subtrees, and only one leaf page entry points to any given table row. It is a one-to-one relationship, just like in a B-tree index.
- PGP_Sym_Encrypt not working in hibernate but works when using the manual insert query
- How do I get asynchronous / event-driven LISTEN/NOTIFY support in Java using a Postgres database?
- Supabase Postgis not working. Topology not in search_path | Change supabase search_path
- How to force PostgreSQL to use index on joined table column?
- hibernate - Postgres- target lists can have at most 1664 entries
- ArrayField max size?
- stop postgres logging endlessly empty statements
- docker-compose .env not loading/applied to container
- postgresql unaccent and case insensitive
- Optimize GROUP BY query to retrieve latest row per user
- Easily viewing postgresql and mysql results that are too wide for the terminal
- How to query based on a associated model condition?
- Difference between text and varchar (character varying)
- PostgreSQL adding carriage return(next line) from a long field's value
- updating table rows in postgres using subquery
- Recursive query to figure out record which creates circular dependency
- postgres deadlock_timeout - how does it work exactly
- PostGIS with invalid memory alloc request size ERROR on polygon transform
- Data-modifying statement in WITH clause seems to run twice
- Supabase connection error "server didn't return client encoding"
- How to create group column based on ids and linked ids in PostgreSQL
- PostgreSQL error: column "qty" is of type integer but expression is of type text
- array_agg DISTINCT and ORDER
- What does "INSERT 0 1" mean after executing direct SQL in PostgreSQL?
- Postgres UPDATE table SET jsonb typed column with javascript var not work for remove an array item
- Using Docker container for Odoo version 18 and Postgres 17
- How do I UPDATE a row in a table or INSERT it if it doesn't exist?
- How to find the first partial match node above a child node in an LTREE
- UPDATE statement on table xxx' expected to update 1 row(s); 0 were matched with Zope transactionmanager
- How to connect PGAdmin 4 to Postgres DB residing in Azure Virtual Network