How to use collaborative filtering to predict users by their behavior?
It seems like a very strange thing to do, but how to predict a certain user by his/her recommendations?
EXAMPLE:
Perhaps, we were making an experiment on how users movie ratings change in time.
And we made a survey in the first year (2019) and in the second (2020) with same users and movies.
But our database has crashed, so we have only users reccomendations in the second year, but we don't know whose recommendations are given.
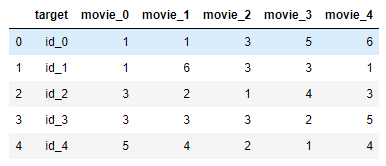
We have: Users-Recommendations matrix in first year, like this one:
And Users-Recommendations matrix in the second year, but without 'target' column:
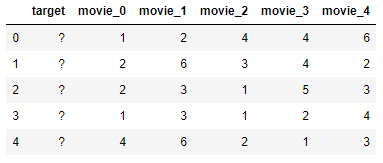
So, by the first year data, we want to recover/predict the 'target' column.
Usually, collaborative filtering is used to predict movie ratings, but this is reversed problem.
Can collaborative filtering still be used?
If yes, what kind of interactions should be made to algorithm in order to solve the problem?
Or is there another approach or ML-algorithm to do this?
Thank you!
P.S.: if you'll attach Python example on similar task, it would be great!
And sorry for not attaching real data and task to this post, I literally can't do this by many reasons :)
There are probably several ways to approach this problem, but I would treat this as an assignment problem. You basically want to assign 2020 movie ratings to users. To do this you have to:
Define the cost of assigning movie ratings to a user. This could be done by defining a distance function between 2020 movie ratings and 2019 movie ratings. An example could be L2-Norm (euclidean distance). So assigning 2020 movie ratings 0 (
[1, 2, 4, 4, 6]) to user id_0 (2019 ratings =[1, 1, 3, 5, 6]) would cost sqrt(3)Build a matrix using your defined distance function reflecting the distance (assignment cost) between each user and each row of 2020 movie ratings
Find the best assignment (with lowest cost) of 2020 movie ratings to users by using hungarian algorithm
- Word Clouds using TabPy
- Extracting lines from two files where there is a match of value in specific columns
- Instantiate empty type-hinted list
- How to fix the GSException: "Container not found" even when the container exists?
- Find index of min value in a matrix
- Break statement in finally block swallows exception
- Does `anaconda` create a separate PYTHONPATH variable for each new environment?
- How can I replace a substring in a Python pathlib.Path?
- How to draw a line on an image in OpenCV?
- Match 2 strings then print both matches
- subprocess and exchanging json: How can I use read() on stdin non-blockingly?
- DNS request with scapy (Python)
- What is the difference between xpath() and findall()?
- if statement in Django template not working
- Extract header/footer from PDF (programmatically)
- How to create virtual env with Python 3?
- Type hinting / annotation (PEP 484) for numpy.ndarray
- Allowing resizing window pyGame
- Python Multiprocessing empty array
- Different / better approaches for calling python function from Java
- Calling Python Functions from Java (Without Jython, because it is too slow.)
- Best way to find the months between two dates
- Calling Java from Python
- Calling Java from Python
- Identifying outliers from openCV contours based on curvature?
- Unfolding a cartesian binned dataset into polar coordinates
- Why is facecolor argument in plot_surface() of matplotlib not working in python?
- Data class with argument optional only in init
- Repl.it Python 3 Short cut Comment/Uncomment a block
- How can I find where Python is installed on Windows?