select rows to read pyspark dataframe based on a latest date value
I have a table like as shown below since the order numbers reoccur based on a date i would like to read just one of them with the latest date. example is just get A1 for 24/03/2022 on pyspark thanks
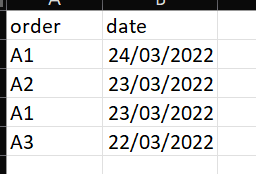
Solution
w = Window.partitionBy('order').orderBy('date')
df = (df
.withColumn('rank',F.row_number().over(w)))
df = (df
.filter(df['rank'] == 1).drop('rank'))
I solved this by ranking the Orders by date and selecting the one with the lowest rank 1
- Simple argparse example wanted: 1 argument, 3 results
- When reading a database table with polars, how do I avoid a SchemaError?
- PIL image size adjustment
- Is there any way to extract header and footer and title page of a PDF document?
- How to ignore Python warnings for complex numbers
- Using list.count to sort a list in-place using .sort() does not work. Why?
- How can I check my python version in cmd?
- Converting from a string to boolean in Python
- How do I sort a dictionary by value?
- How to check what types are in defined types.UnionType?
- None default values in XGBoost regressor model
- Creating multiple instances of wx.App - is it ok?
- How to convert pine script stdev to python code?
- Python SQL query string formatting
- How to get the timestamps of lyrics in songs?
- Is there a way to tell if a function's return value is used?
- Remove rows in a 2d-numpy array if they contain a specific element
- What is the best approach to use Web Sockets with Django projects?
- How do I use Twisted (or Autobahn) to connect to a socket.io server?
- Running several ApplicationSessions non-blockingly using autbahn.asyncio.wamp
- Autobahn cannot import name error
- WSGI compliant component with web socket client?
- Autobahn: catch sendMessage error
- How do I display UTF-8 characters sent through a websocket?
- Python tkinter grid manager?
- How to drop into REPL (Read, Eval, Print, Loop) from Python code
- Kivy GUI with autobahn WAMP
- Removing specific pattern from a string using regex in python
- Match all lines with a pattern after a text until pattern matching failure regex
- Match word "A". If "B" is next word, match too