Alternate background colors in styled pandas df that also apply to MultiIndex in python pandas
SETUP
I have the following df:
import pandas as pd
import numpy as np
arrays = [
np.array(["fruit", "fruit", "fruit","vegetable", "vegetable", "vegetable"]),
np.array(["one", "two", "total", "one", "two", "total"]),
]
df = pd.DataFrame(np.random.randn(6, 4), index=arrays)
df.index.set_names(['item','count'],inplace=True)
def style_total(s):
m = s.index.get_level_values('count') == 'total'
return np.where(m, 'font-weight: bold; background-color: #D2D2D2', None)
def style_total_index(s):
return np.where(s == 'total', 'font-weight: bold; background-color: #D2D2D2','')
(df
.style
.apply_index(style_total_index)
.apply(style_total)
)
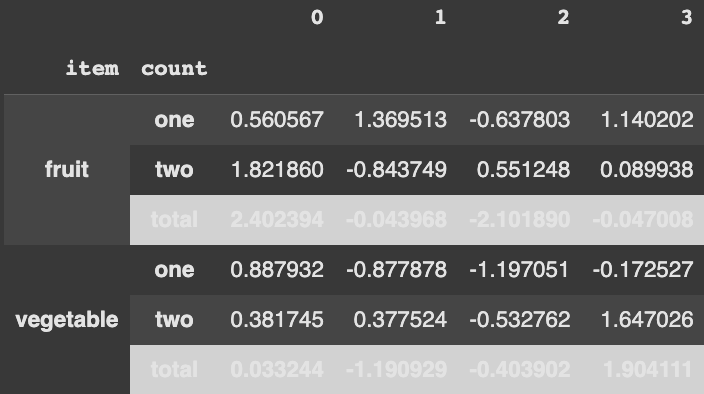
WHAT I WANT TO DO/DESIRED OUTPUT
I would like to apply alternating background colors to each row (as well as the MultiIndex) while still keeping the separately colored and formatted total row. Here is a visual example of what I am trying to accomplish:
As you can see, all rows as well as the MultiIndex are alternating colors with the total keeping its own custom formatting.
WHAT I HAVE TRIED
I have tried a whole bunch of things. I came across this question and this question that both use set_table_styles(), however, this issue on the pandas Github says that "Styler.set_table_styles is not exported to excel. This will not be change...". So, set_table_styles() is not an option here. How can I go about achieving the desired output?
Here's one approach:
- Using
np.resize - See below for
itertools.cycleoption.
def style_total_index(s, colors, color_map, total):
# `s` is series with index level values as *values*, name 0 for level 0, etc.
level = s.name
if level == 0:
# level 0 is quite easy:
# check if `s` equals its shift + `cumsum` result.
# `result % 2 == 1` gets us `True` for 1st ('fruit'), 3rd, etc. value,
# and `False` for 2nd ('vegetable'), 4th, etc.
# these boolean values we map onto the colors with `color_map`.
style = (s.ne(s.shift()).cumsum() % 2 == 1).map(color_map)
else:
# level 1:
# check `s` == 'total' + shift (with `False` for 1st NaN) + `cumsum`.
# `groupby` and `transform` to resize `colors` to match size of group.
# mask to add `total` style
style = s.eq('total').shift(fill_value=False).cumsum()
style = style.groupby(style).transform(lambda x:
np.resize(colors, len(x))
)
style = style.mask(s == 'total', total)
return style
def style_total(s, colors, total):
# `s` is series (a column) with index like `df`
# so, similar to `level=1` above, but access `s.index.get_level_values(1)`
# and convert that to a series before checking equal to 'total'.
# rest the same.
style = (s.index.get_level_values(1).to_series().eq('total')
.shift(fill_value=False).cumsum()
)
style = style.groupby(style).transform(lambda x: np.resize(colors, len(x)))
style = style.mask(s.index.get_level_values(1) == 'total', total)
return style.values
# using `np.random.seed(0)` for reproducibility
colors = ['background-color: #CFE2F3', 'background-color: #FFF2CC']
total = 'font-weight: bold; background-color: #D2D2D2'
color_map = {k: color for k, color in zip([True, False], colors)}
df_styled = (df
.style
.apply_index(style_total_index, colors=colors, color_map=color_map,
total=total)
.apply(style_total, colors=colors, total=total)
)
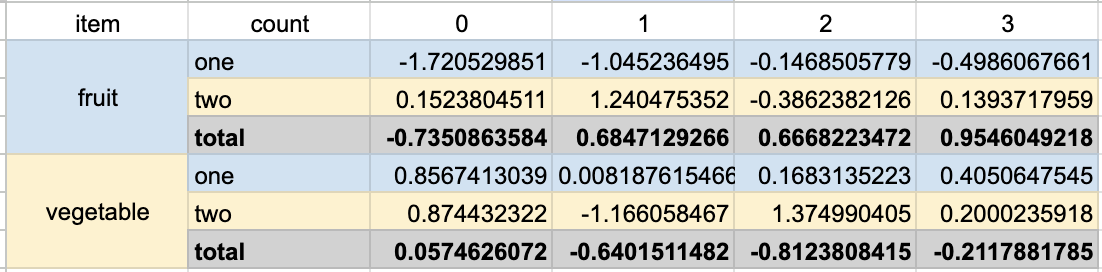
df_styled
Output:
Export to Excel (for the header setting, cf. here):
# removing default formatting for header
from pandas.io.formats import excel
excel.ExcelFormatter.header_style = None
df_styled.to_excel('df_styled.xlsx')
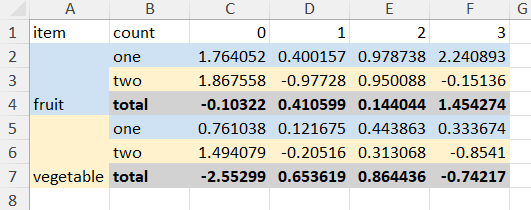
Output Excel:
The above method is set up to handle the situation in which unique level-0 values might have an uneven number of associated rows. That is to say, I have assumed that each level-0 needs to start with #CFE2F3 (light blue), regardless of whether the previous group of rows ended with that color. E.g., suppose we add an extra row only for 'fruit', the above gets us:
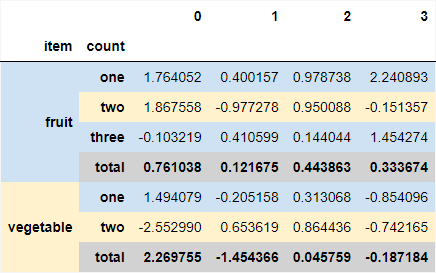
If you just want to 'cycle' through regardless of the transition to a new group, here's an approach that uses cycle from itertools:
from itertools import cycle
def style_total_index(s, colors, color_map, total):
level = s.name
if level == 0:
style = (s.ne(s.shift()).cumsum() % 2 == 1).map(color_map)
else:
colors_cycle = cycle(colors)
style = [next(colors_cycle) if i != 'total' else total
for i in df.index.get_level_values(level)]
return style
def style_total(s, colors, total):
level = 'count'
colors_cycle = cycle(colors)
style = [next(colors_cycle) if i != 'total' else total
for i in df.index.get_level_values(level)]
return style
colors = ['background-color: #CFE2F3', 'background-color: #FFF2CC']
total = 'font-weight: bold; background-color: #D2D2D2'
color_map = {k: color for k, color in zip([True, False], colors)}
df_styled = (df
.style
.apply_index(style_total_index, colors=colors, color_map=color_map,
total=total)
.apply(style_total, colors=colors, total=total)
)
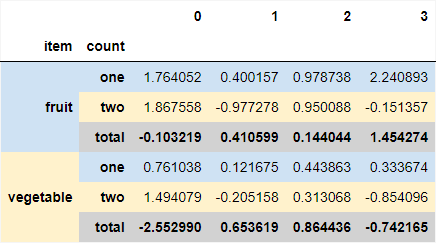
df_styled
Output:
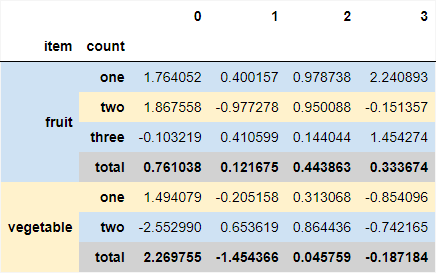
Of course, both of these methods are adjustable to reach whatever alternation with a bit of tweaking.
- Word Clouds using TabPy
- Extracting lines from two files where there is a match of value in specific columns
- Instantiate empty type-hinted list
- How to fix the GSException: "Container not found" even when the container exists?
- Find index of min value in a matrix
- Break statement in finally block swallows exception
- Does `anaconda` create a separate PYTHONPATH variable for each new environment?
- How can I replace a substring in a Python pathlib.Path?
- How to draw a line on an image in OpenCV?
- Match 2 strings then print both matches
- subprocess and exchanging json: How can I use read() on stdin non-blockingly?
- DNS request with scapy (Python)
- What is the difference between xpath() and findall()?
- if statement in Django template not working
- Extract header/footer from PDF (programmatically)
- How to create virtual env with Python 3?
- Type hinting / annotation (PEP 484) for numpy.ndarray
- Allowing resizing window pyGame
- Python Multiprocessing empty array
- Different / better approaches for calling python function from Java
- Calling Python Functions from Java (Without Jython, because it is too slow.)
- Best way to find the months between two dates
- Calling Java from Python
- Calling Java from Python
- Identifying outliers from openCV contours based on curvature?
- Unfolding a cartesian binned dataset into polar coordinates
- Why is facecolor argument in plot_surface() of matplotlib not working in python?
- Data class with argument optional only in init
- Repl.it Python 3 Short cut Comment/Uncomment a block
- How can I find where Python is installed on Windows?