Bit Aligning for Space and Performance Boosts
In the book Game Coding Complete, 3rd Edition, the author mentions a technique to both reduce data structure size and increase access performance. In essence it relies on the fact that you gain performance when member variables are memory aligned. This is an obvious potential optimization that compilers would take advantage of, but by making sure each variable is aligned they end up bloating the size of the data structure.
Or that was his claim at least.
The real performance increase, he states, is by using your brain and ensuring that your structure is properly designed to take take advantage of speed increases while preventing the compiler bloat. He provides the following code snippet:
#pragma pack( push, 1 )
struct SlowStruct
{
char c;
__int64 a;
int b;
char d;
};
struct FastStruct
{
__int64 a;
int b;
char c;
char d;
char unused[ 2 ]; // fill to 8-byte boundary for array use
};
#pragma pack( pop )
Using the above struct objects in an unspecified test he reports a performance increase of 15.6% (222ms compared to 192ms) and a smaller size for the FastStruct. This all makes sense on paper to me, but it fails to hold up under my testing:
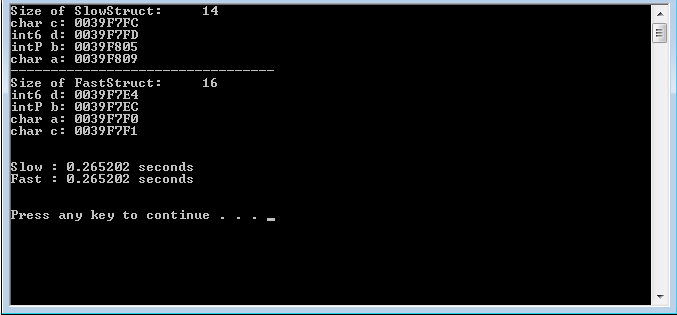
Same time results and size (counting for the char unused[ 2 ])!
Now if the #pragma pack( push, 1 ) is isolated only to FastStruct (or removed completely) we do see a difference:
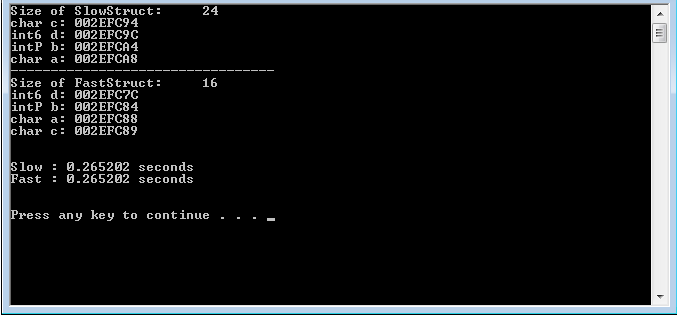
So, finally, here lies the question: Do modern compilers (VS2010 specifically) already optimize for the bit alignment, hence the lack of performance increase (but increase the structure size as a side-affect, like Mike Mcshaffry stated)? Or is my test not intensive enough/inconclusive to return any significant results?
For the tests I did a variety of tasks from math operations, column-major multi-dimensional array traversing/checking, matrix operations, etc. on the unaligned __int64 member. None of which produced different results for either structure.
In the end, even if their was no performance increase, this is still a useful tidbit to keep in mind for keeping memory usage to a minimum. But I would love it if there was a performance boost (no matter how minor) that I am just not seeing.
It is highly dependent on the hardware.
Let me demonstrate:
#pragma pack( push, 1 )
struct SlowStruct
{
char c;
__int64 a;
int b;
char d;
};
struct FastStruct
{
__int64 a;
int b;
char c;
char d;
char unused[ 2 ]; // fill to 8-byte boundary for array use
};
#pragma pack( pop )
int main (void){
int x = 1000;
int iterations = 10000000;
SlowStruct *slow = new SlowStruct[x];
FastStruct *fast = new FastStruct[x];
// Warm the cache.
memset(slow,0,x * sizeof(SlowStruct));
clock_t time0 = clock();
for (int c = 0; c < iterations; c++){
for (int i = 0; i < x; i++){
slow[i].a += c;
}
}
clock_t time1 = clock();
cout << "slow = " << (double)(time1 - time0) / CLOCKS_PER_SEC << endl;
// Warm the cache.
memset(fast,0,x * sizeof(FastStruct));
time1 = clock();
for (int c = 0; c < iterations; c++){
for (int i = 0; i < x; i++){
fast[i].a += c;
}
}
clock_t time2 = clock();
cout << "fast = " << (double)(time2 - time1) / CLOCKS_PER_SEC << endl;
// Print to avoid Dead Code Elimination
__int64 sum = 0;
for (int c = 0; c < x; c++){
sum += slow[c].a;
sum += fast[c].a;
}
cout << "sum = " << sum << endl;
return 0;
}
Core i7 920 @ 3.5 GHz
slow = 4.578
fast = 4.434
sum = 99999990000000000
Okay, not much difference. But it's still consistent over multiple runs.
So the alignment makes a small difference on Nehalem Core i7.
Intel Xeon X5482 Harpertown @ 3.2 GHz (Core 2 - generation Xeon)
slow = 22.803
fast = 3.669
sum = 99999990000000000
Now take a look...
6.2x faster!!!
Conclusion:
You see the results. You decide whether or not it's worth your time to do these optimizations.
EDIT :
Same benchmarks but without the #pragma pack:
Core i7 920 @ 3.5 GHz
slow = 4.49
fast = 4.442
sum = 99999990000000000
Intel Xeon X5482 Harpertown @ 3.2 GHz
slow = 3.684
fast = 3.717
sum = 99999990000000000
- The Core i7 numbers didn't change. Apparently it can handle misalignment without trouble for this benchmark.
- The Core 2 Xeon now shows the same times for both versions. This confirms that misalignment is a problem on the Core 2 architecture.
Taken from my comment:
If you leave out the #pragma pack, the compiler will keep everything aligned so you don't see this issue. So this is actually an example of what could happen if you misuse #pragma pack.
- How to print the data of a C structure in Windbg
- How does this code find duplicate characters in a string?
- Does there exist a reversed comma operator in C?
- C struct assignment by unnamed struct initialized by member-wise list, syntax candy or unintentional memory overhead?
- How do I assert that two pointers are equal with GLib's testing framework?
- Random password generator + algorithm
- C: printf a float value
- Weird behaviour of Java FFM on Windows platform when creating upcalls accepting both structure and pointer parameters
- How does C know that you're out of bounds in a multi dimensional array?
- Stack vs. heap pointers in C
- Writing a Von Neumann Ordinal generator in C : Problem with malloc
- multiple definition of main first defined here
- Justification of storing metadata in 2 least significant bits of address
- MIN and MAX in C
- Comma in C/C++ macro
- How can I pass several arguments through a single void pointer argument?
- C - determine if a number is prime
- Implementation of __builtin_clz
- Modern Delphi to C strings for passing to C DLLs
- How to compile and run C files from within Notepad++ using NppExec plugin?
- Is it safe to close a duplicated token handle during impersonating with ImpersonateLoggedOnUser?
- C - Error is "free(): invalid next size (normal) "
- GtkTreeStore Subclass, Error When Reloading Plugin
- Elegant way to define an automatic variable with specific alignment
- error LNK2005: xxx already defined in MSVCRT.lib(MSVCR100.dll) C:\something\LIBCMT.lib(setlocal.obj)
- Is the C programming language object-oriented?
- Standard alternative to GCC's ##__VA_ARGS__ trick?
- Why is malloc returning NULL here?
- What does "for (;;)" (for keyword followed by a pair of semicolons in parentheses) mean?
- Can I programming OpenGL4+ in a card that support 2.1 only?