I'm currently conducting a meta-analysis study. In my study, there are several studies that reported multiple outcomes. According to the literature, I figured out that the multilevel meta-analysis could be a good way to combine these multiple outcomes.
However, when I did the analysis, some problem occurred as I briefly summarized in my title. I used the metafor package in R and I'd like to use the tutorial example to explain. You can find the link of this tutorial below (I will attach essential detail in this question page):
https://www.metafor-project.org/doku.php/tips:forest_plot_with_aggregated_values
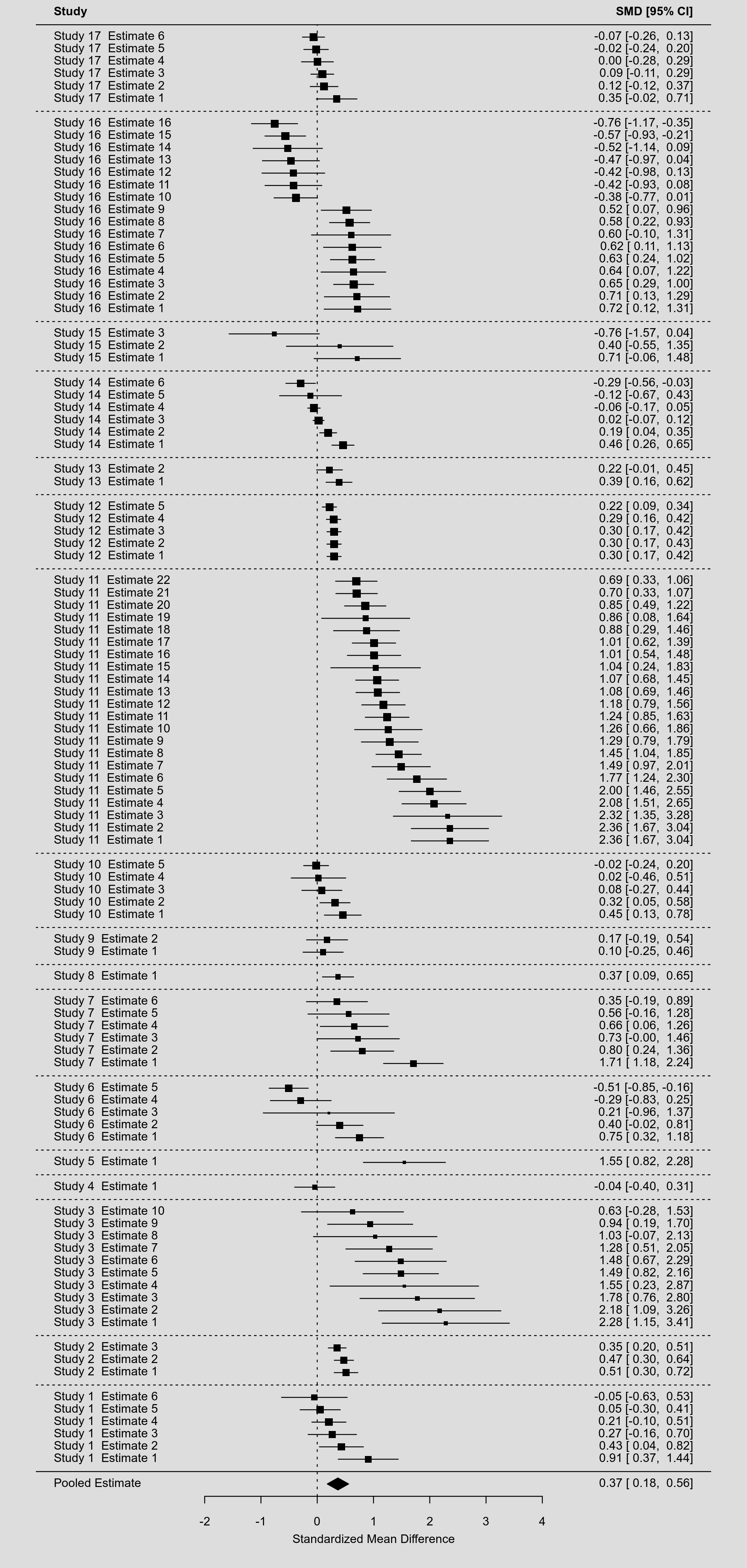
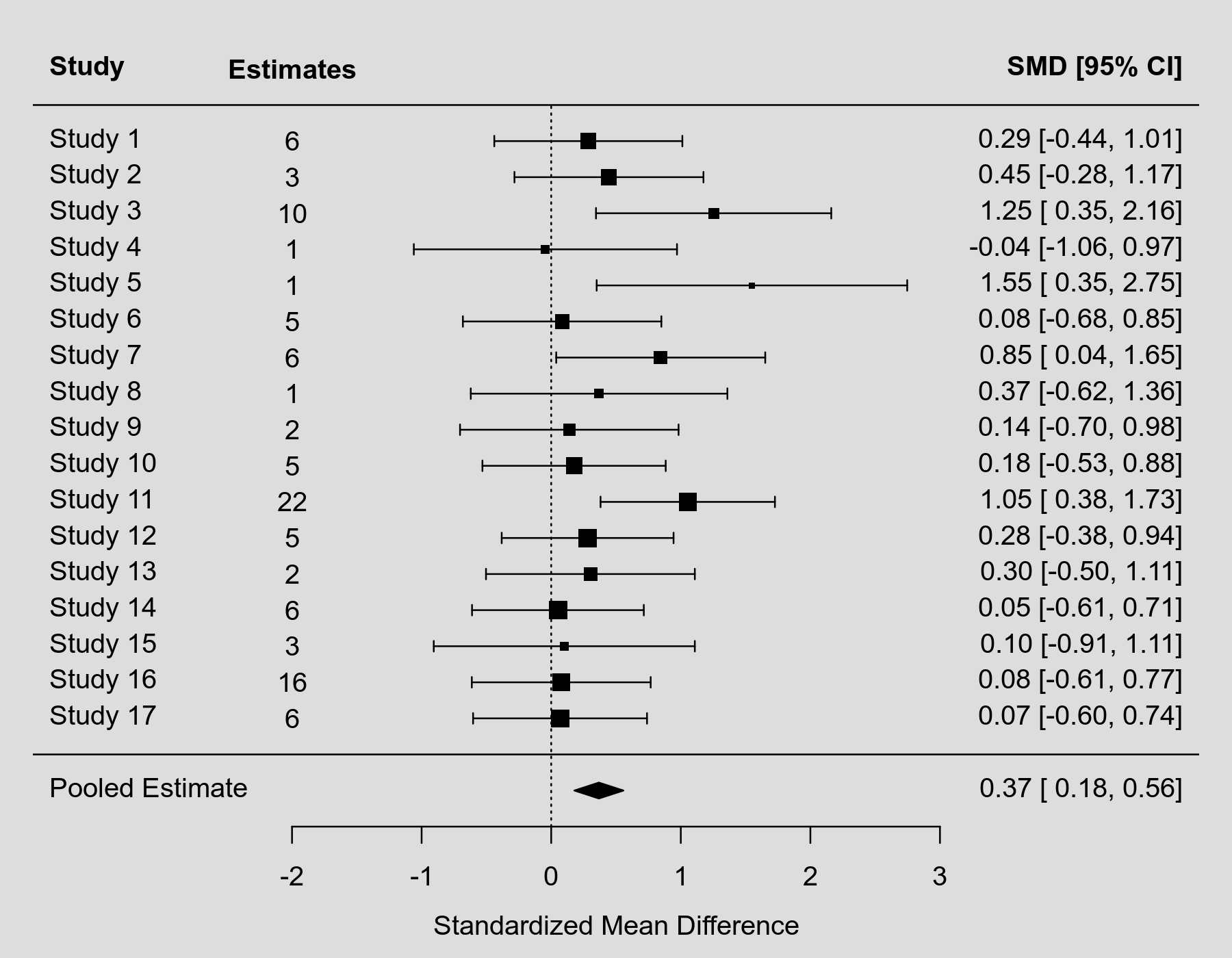
The problem is that in this example, while study 4, 5, and 8 only have one estimate, after aggregation, their confidence intervals expand and even expand from a significant level to a non-significant level.
Moreover, in the final aggregated forest plot, several studies' confidence intervals include 0, but the summary estimate doesn't include 0. Isn't it a bit counter-intuitive?
Since the specific mathematical process of the multi-level model and aggregate() function is a black box for me, I asked chatgpt why could that occur. It answered me that because studies that reported multiple outcomes are given more precision while studies that reported only one outcomes are considered less precise.
Firstly, I'm not sure whether chatgpt got the point. Secondly, I think most applied researchers don't know the specific process behind the multi-level model, either. So, could it be problematic when this counter-intuitive aggregated forest plot is inspected?
The type of aggregations discussed at that link is a specific case where one would like to create an aggregated dataset (using information from the multilevel model) such that a simple meta-analysis of the aggregated values (using an equal-effects model) produces the same result as the multilevel model. This requires calculating the sampling variances of the aggregated values in such a way that they incorporate the heterogeneity stemming from the multilevel model. As a result, CIs get wider, also for the studies that only supply a single estimate to the model.
As for the fact that most CIs around the aggregated values include 0, while the CI around the summary estimate excludes 0: That is kind of the idea behind a meta-analysis. If individual estimates are imprecise, then the pooled estimate can still be sufficiently precise to achieve statistical significance, assuming that there is a consistent pattern/signal. In fact, 16 out of the 17 aggregated values are positive. That in itself has a very low probability of occurring under the null hypothesis (in which case the sign of each estimate should either be randomly positive or negative). A simple sign test of this can be obtained with prop.test(16, 17).
{kind=link}
{kind=link}